Personal Empirical Project Setup
This is a very short guide on how to setup a project involving codes and data for either economic analysis (industry) or research (academia). This fully draws from my limited experience working in different projects in government organizations, private companies and academia. The code is still in full development, please feel free to contact me if you disagree with the method shown here or if you have any suggestions!
The guide is divided in the following sections: in section 1 we explain the general folder structure for single tasks and for simple work. In section 2 we give some very basic information on how to write clean and effective codes. In folder 2 we explain a more complex structure, for more advanced projects which require version control. In section 3 we introduce git and github as tools for versioning codes and drafts. In section 4 we explain some quality of life tools, such as vscode, or libraries to speed up processes (gtools, parallel computing etc).
Simple Folder Structure:
When working in a simple project, which generally only requires minimal version control and limited use of advanced tools such as cluster servers, I find this type of structure to be the most useful.
├───01 Load
│ └───Load dataset 1
│ ├───_aux
│ ├───_raw
│ ├───_temp
│ ├───dta
│ └─ 00 run all.do
│ └─ 01 Load first dataset.do
│ └─ 02 export first datset.do
├───02 Clean
│ └───Clean dataset 1
│ ├───_aux
│ ├───_temp
│ ├───dta
│ └─ 00 run all.do
│ └─ 01 apply mappings.do
│ └─ 02 clean.do
│ └─ 03 export.do
└───03 Analysis
│ └───descriptive_stats
│ ├───_aux
│ ├───_temp
│ ├───out
│ └─ 00 run all.do
│ └─ 01 create descriptives.do
│ └─ 02 format descriptives.do
Here we take the example of a dataset (dataset 1) being loaded, cleaned and used as part of an analysis.
The first task loads the dataset, it can be either importing a bunch of excel files, scraping a dataset or something similar.
Generally the rawest possible files (the ones generally received from an external source) are located in the “_raw” folder. The files are then cleaned in the code and exported in the “dta” folder.
The “_aux” and “_temp” folders serve two specific purposes: in “_aux” we generally include all the mapping files. In general we want to avoid our code to have code blocks like this:
replace x = "newname" if x == "oldname"
replace x = "newname1" if x == "oldname1"
replace x = "newname2" if x == "oldname2"
...
Because this approach is extremely prone to error and it makes the codes difficult to navigate. Instead, it is better to load an external mapping (aux) file, that converts the old values in the new ones. It can be an excel file, a dta or any format that is easy to navigate and that can be manually adjusted if needed. Generally we like to refer to aux files for any manual mappings/hard coded values, so that they are easy to refer to and to inspect from auditors or data editors.
An example of a mapping file in excel would be:
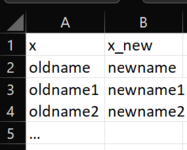
Finally, the “_temp” folder is self explanatory, as it should only contain temporary files, these are the files that are created by an intermediate dofile and are used in a following dofile. They are not final outputs of the folder and therefore should not be in the “dta” folder
So in summary the different folder namings represent:
- _raw: raw files from external source
- _aux: mapping files
- _temp: temporary outputs
- dta: loaded datasets
The “Clean” folder should NOT contain a _raw subfolder, when possible and should simply take the loaded datasets from the “Load” folder, pass them through some cleaning codes and output the resulting datasets.
Please: DO NOT COPY PASTE FILES MANUALLY! If a dataset is created in the “Load” folder, it should stay there, then the “Clean” codes can take it from the “Load/dta” folder and output it in the “Clean/dta” folder.
Manually moving files creates confusion as to where these files have been produced.
Finally the Analysis folder should simply take the loaded and cleaned files from “Clean/dta” and output the results in the “Analysis/out” subfolder (or in the draft folder if it is located somewhere else).
As usual, do not manually move files, or worse, do not rename tables from when they come out of the codes to when they are loaded in the draft. as that creates confusion on which codes create which tables.
Generally it may happen that tables created from stata or python are not well formatted. A solution would be to have a out/_formatted folder, where the tables are manually formatted. Please remember to keep the same table names and to reformat tables whenever the code is rerun. Avoid manually formatting whenever possible.
General Code Guidelines
Whenever writing a new piece of code, a few key points should be respected:
- Keep single codes short and limited to 1 or 2 tasks
Writing 5 100-lines pieces of code that are limited to a few tasks, is much better than a single piece of code of 500+ lines that does everything. -
Put an appropriate header with description of the work
************************************ * Name: * Date: * Description: * Input: * Output: ************************************ * Setup (or import libraries if in python) capture log close clear all * paths main = "" load = "$main/01 Load/" clean = "$main/02 Clean/" analysis = "$main/03 Analysis/" raw = "$load/_raw/" temp = "$load/_temp/" dta = "$load/dta/" ... -
Separate code sections
************************************ * Load and merge dataset ************************************ * Use file1 from Nestle use file1.dta, clear * Merge with products mappings and save merge using $aux/file2, assert(3) nogen save "$temp/file1_loaded_merged.dta", replacde - Indent code
Python requires scode to be indented, while other programs do not. Always indenting inside loops, if/else conditions and so on is a good practice even when indenting is not required. -
Short and effective comments (not redundant)
What you should not do:* merge data1 with data2 merge m:1 using data2I aleady know the datasets are called data1 and data2 and I can read that you are merging them, this comment is useless.
What you should do:
* merge nestle dataset with product names merge m:1 using data2 -
Simple code is always always better than complex clever code (unless there are evident speed advantages)
Whenever I see a double nested loop I generally question wether it is useful or not. Always have a preference for clear, easy to read code than for complex nested loops, which are difficult to debug and to interpret.Sometimes complex code sometimes is required. In that case, say WHY you are doing certain things, instead of repeating WHAT you are doing. (the WHAT is readable from the code, the WHY is not!)
More Complex Folder Structure:
There are cases in which you might want to separate codes and data. I am still new to this so this might not be the best guide for this, so if you find anything that could improve this please let me know.
Version control is an extremely useful tool, but it might work best when codes and data are separated, as we want to only track changes in codes and not in data.
The following structure is currently used in one of the projects I am working on, and I am currently testing it, so this might change in the future.
├───Codes
│ ├───01 Load
│ │ └───load dataset 1
│ ├───02 Clean
│ │ └───apply mappings
│ └───03 Analysis
│ └───descritptive stats
├───Data
│ ├───_temp
│ ├───01 Raw
│ │ └───dataset_nestle
│ ├───02 Mappings
│ │ └───mappings_nestle
│ └───03 Consolidated
│ │ └───dataset1
└───Outputs
└───descriptive stats
The advantage of this setting is that we can keep the codes and data separated.
The clear disadvantage is that it is really easy to lose track of which codes creates what!
Generally a good rule of thumb is to keep the same names between the codes and data and to keep in a README.md file in main the order in which files should be run and what is the input and output of each folder.
Version Control: Git and Github
Git is an extremely powerful software developed by Linus Tovalds (the Linux creator) which has become the gold standard for version control for developers.
Version control was not something done often by economists, but it is starting to grow as the need for replicable results grows.
Github is just a hosting platform for git-controlled software.
The idea behind version control is that we want to keep track of the results of our code at any point in time, and be able to replicate results that weere produced months or years earlier.
Another advantage is not having to create seven different versions of the same code.
A few git commands are reported here, full git guide coming soon: These are basically all the commands you should ever know
# Add files to the git controlled environment
git add "filename"
# Add all files and folders
git add *
# Create a snapshot of the code with the following title
git commit -m "title"
# Push the code to the online repository
git push
# Pull code from online repository
git pull
# Branch code in a separate stream
git branch branch1
# move among different branches
git checkout brach1
# come back to the "master" branch
git checkout master
# merge the current branch with branch1
git merge branch1
Quality of life tools
- vscode
- See guide for using vscode and stata here: gdeiana.github.io/economics/stata-vscode/
- Stata libraries:
- gtools
- reghdfe
- python libraries:
- multiprocessing for running processes in parallel,
guide here:
https://www.youtube.com/watch?v=fKl2JW_qrso&t=1632s&ab_channel=CoreySchafer
- multiprocessing for running processes in parallel,
- R tools:
- multiprocessing: using foreach and %dopar%